
饼干哥哥饼干哥哥饼干哥哥AGI2026年2月6日 11:16广东
饼干我啊,昨晚「乌鸦嘴」了
昨晚跟朋友深夜聊 AI 跨境电商,说最近 Sora2 成本飙升且降智,很明显就是要发新模型了。
然后突然意识到很久都没有大规模的新模型轰炸了,估计快要发了
这几天要好好休息做好过年连轴转的准备吧
昨晚睡前还在安排行程
结果,卧槽,早上7 点起来就看到海外GPT、Claude两个死对头前后脚突袭发新模型,搞得我惊坐起后蓬头垢脸地刷海外的帖子整理信息。
这波更新,让我意识到,2026 年AI 的关键词一定是「洗牌」
例如最近 Sora2 的问题让大家意识到,视频这块,OpenAI 的技术门槛还是很大的,关键时刻VEO 还插不进来,更别说国产模型没一个能打的。
这次 Claude、GPT 的更新也像是在洗 AI编程 领域的牌。
好了,废话少说,直接讲发生了什么。
太长不看版,直接划重点:
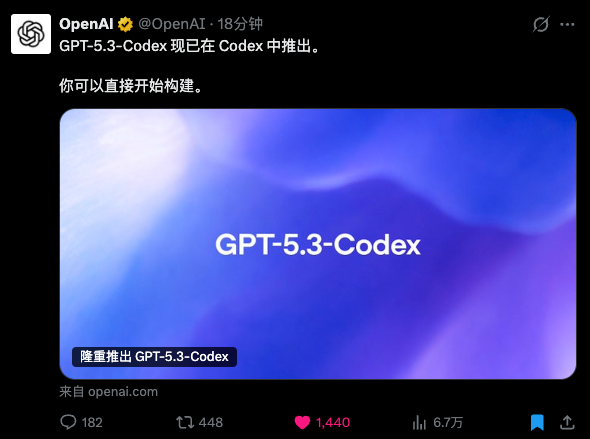
- 1. OpenAI 玩大的: GPT-5.3-Codex 是第一个由 AI 自己参与构建的 AI,自我进化开始了。它在写代码、修 Bug 上比 GPT-5.2 快了 25%,更是拿下了 77.3% 的终端操作高分,基本就是个能独立干活的超级工程师。
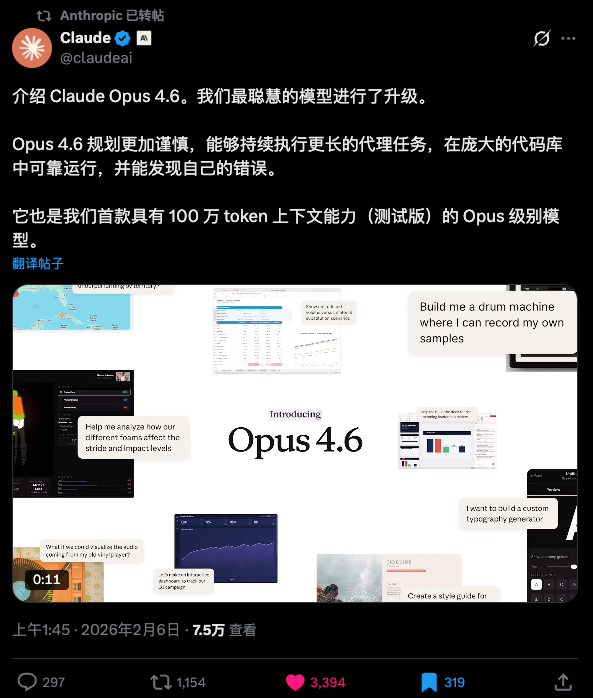
- 2. Anthropic 也是狠人: Claude Opus 4.6 终于上了 1M 上下文,而且解决了“长文记不住”的毛病,召回率高达 76%。它现在有了“自适应思考”能力,能根据任务难度决定想多久,省钱又聪明。
- 3. Gemini 现在的处境: 尴尬。在纯编程和 Agent 任务上,被这两家按在地上摩擦。Gemini 3 Pro 在长文本上虽然宣称强,但实际跑分不如 Opus 4.6 稳。全村的希望都在传闻中 2 月发布的 Gemini 3.5 上了。
- 4. 黄金搭档还得用: 别想着用一个模型通吃。最佳实践依然是 Claude 做架构师(想得深),GPT 做执行者(跑得快)。
如果说昨天我们还在研究怎么写 Prompt 讨好 AI,今天过后,你可能得学会怎么像老板一样管理这一群“硅基员工”了。
01
真的变天了:AI 开始自己造 AI
先说 OpenAI 这边的 GPT-5.3-Codex。
这次更新最让我起鸡皮疙瘩的不是跑分,而是技术文档里轻描淡写的一句话:“这是我们第一个在创造自己的过程中,发挥了关键作用的模型。”
这句话什么意思?就是 OpenAI 的工程师在开发 GPT-5.3 的时候,已经开始用老版本的模型来写训练代码、找 Bug、甚至管理部署流程了。人类在这个闭环里,正在逐渐从“操作员”变成“监工”。这种自我进化的速度直接体现在了效率上——GPT-5.3-Codex 的推理速度比 GPT-5.2 提升了 25%。
在实战能力上,这货简直是“杀疯了”。
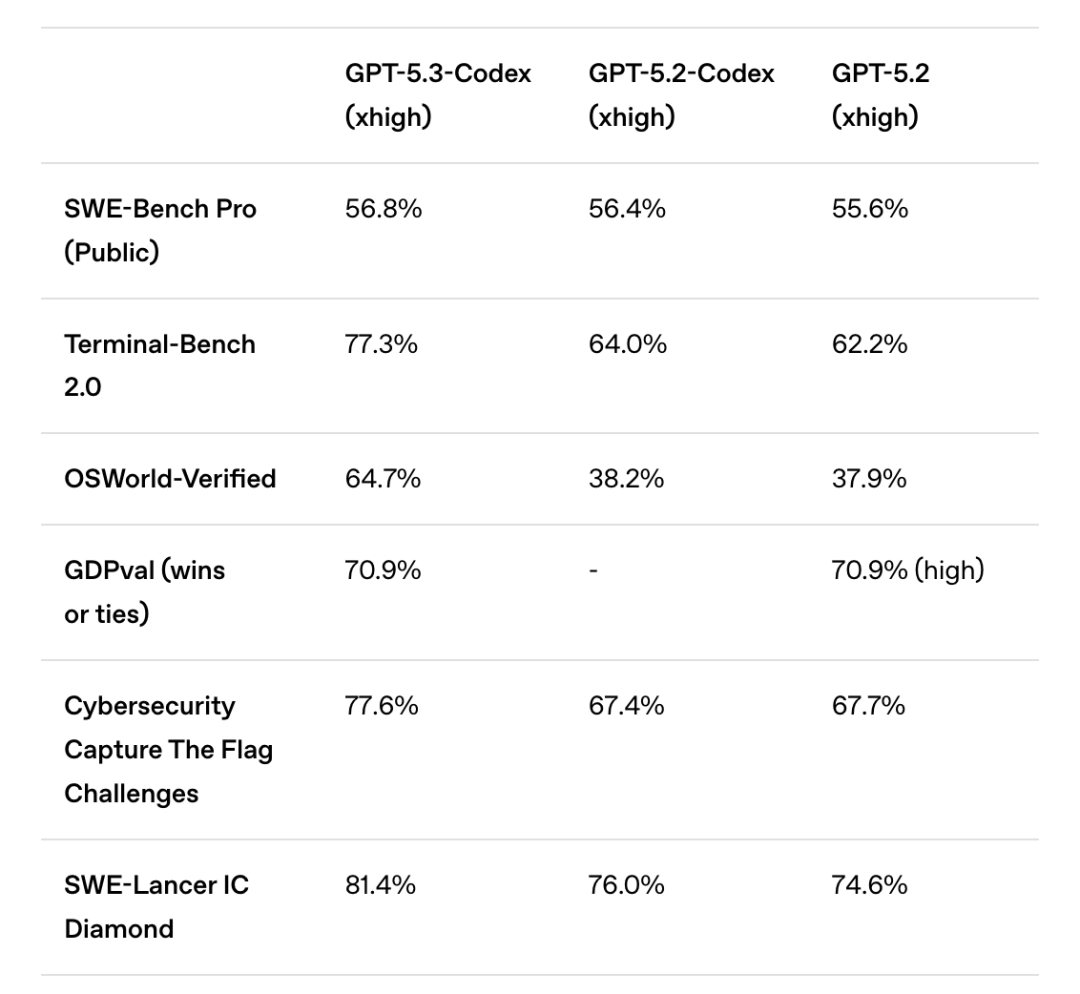
我们看一个数据:Terminal-Bench 2.0(命令行操作基准测试)。这是真刀真枪在终端里写代码、跑环境的测试。GPT-5.2 的得分是 64.7%,而 GPT-5.3-Codex 直接干到了 77.3%。
以前我们觉得 AI 是副驾驶(Copilot),帮你补全两行代码。现在它不仅想握方向盘,甚至想自己修发动机。
OpenAI 展示了它在几天内从零构建的一款赛车游戏,连地图、道具系统都给你整得明明白白,甚至还能一边跑一边让你微调。
这就意味着,对于那些枯燥的、重复的、甚至稍微有点复杂的工程化难题,GPT-5.3-Codex 已经不仅仅是“能用”,而是“好用”了。
02
告别金鱼记忆,Claude 这次是来真的
再看隔壁 Anthropic,也是憋了个大招。
之前的 Claude Opus 4.5 虽然好用,但有个致命痛点:上下文腐蚀(Context Rot)。号称支持 200k 长文本,一旦真的塞满,它就开始顾头不顾尾,中间的信息经常丢。
这次 Opus 4.6 带来的 1M(100万)上下文窗口,不是数字游戏,是质变。
在 MRCR v2(长文本大海捞针)测试里,前代 Sonnet 4.5 的召回率只有惨不忍睹的 18.5%,基本就是瞎蒙。而 Opus 4.6 直接干到了 76%。
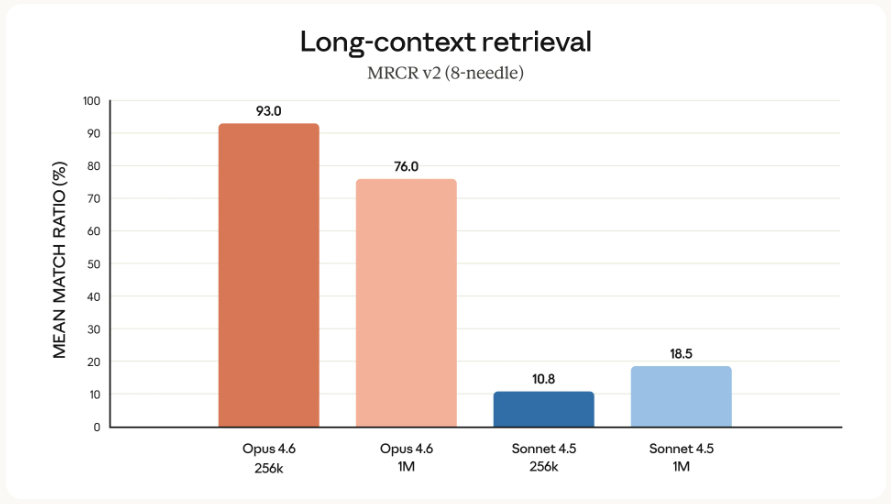
这是什么概念?你可以把几百页的财报、几十万字的代码库直接扔给它,它不仅能读完,还能精准地告诉你第 342 页脚注里的数据和第 10 页的逻辑冲突了。
更绝的是,Anthropic 这次把“脑子”也升级了。Opus 4.6 引入了 Adaptive Thinking(自适应思考)。以前用模型,要么傻快,要么死慢。现在它能自己判断:遇到简单问题秒回;遇到复杂逻辑,它会自己决定“多想一会儿”。
这就很像一个成熟的高级员工,不用你盯着,他知道轻重缓急。
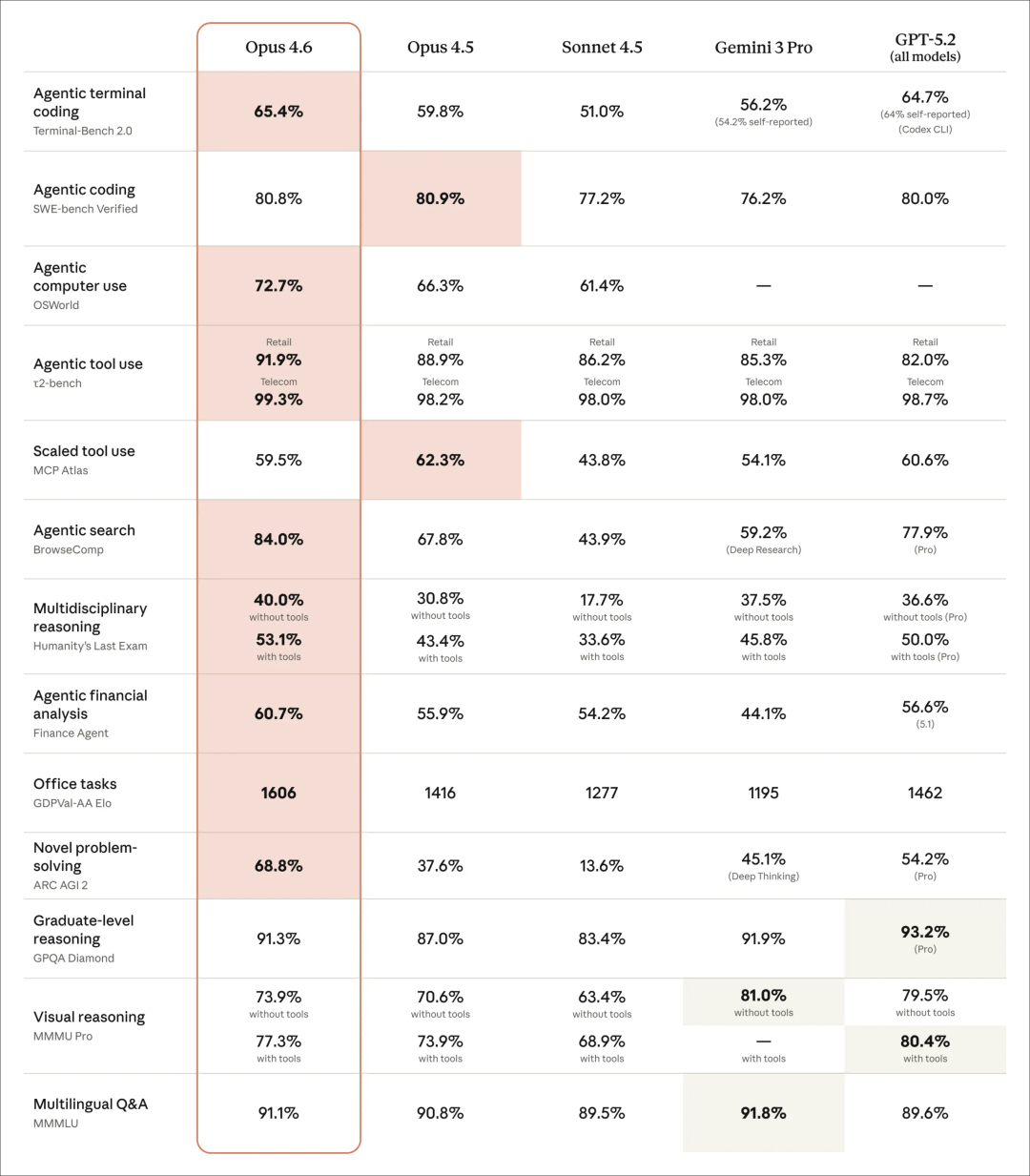
在 GDPval-AA(针对金融、法律等高价值任务评估)中,Opus 4.6 的 Elo 得分比业界第二(GPT-5.2)高出了整整 144 分。这说明在处理复杂的商业决策、法律文书分析时,Claude 依然是那个心思缜密的“文科状元”。
03
别被跑分骗了,这两个模型的路子完全不同
这次两家同时发布,很多人第一反应是比分高低。其实,仔细看就会发现,这两家公司的路子已经分叉了。
Claude Opus 4.6 是“高权限的自主代理”。
它像是一个深思熟虑的架构师。Anthropic 这次推出的 Agent Teams 功能,允许一个 Claude 充当 Team Lead,指挥其他 Claude 分头干活。
比如做代码审查,它可以让一个分身看前端,一个看后端,一个查数据库,最后汇总报告。它更强调规划(Planning)和长逻辑链的稳定性。
GPT-5.3-Codex 是“随时响应的实干家”。
它更像是一个手速极快的资深工程师。OpenAI 强调的是交互性(Interactive)。你可以在它干活的过程中随时插嘴,微调方向,而不是等它干完了再返工。
它在 OSWorld-Verified(操作电脑)测试上的巨大提升(从 38.2% 跃升至 64.7%),说明它更擅长跟计算机系统、命令行这些“硬”东西打交道。

简单总结:
- 需要想清楚大方向、查漏补缺、读长文档? 选 Claude。
- 需要快速写代码、跑环境、修 Bug、搞定落地页? 选 GPT。
所以,现在的最佳实践流程应该是这样:
- 1. 架构与审计(The Boss): 把需求甩给 Claude Opus 4.6。让它利用 1M 上下文通读你的整个项目文档,设计技术方案,或者进行深度的代码审查。它的逻辑严密,能发现那些隐蔽的架构漏洞。
- 2. 执行与修复(The Worker): 拿着 Claude 定好的方案,交给 GPT-5.3-Codex 去落地。利用它 25% 的速度提升和强大的终端操作能力,快速生成代码、跑通测试、修复具体的报错。
- 3. 循环迭代: Codex 搞不定或者改乱了的时候,再把代码扔回给 Claude 让他“评理”。
这种“Opus 脑 + Codex 手”的组合,在未来很长一段时间内,依然是单兵作战的效率天花板。
04
Gemini 3 Pro 现在的处境很尴尬
这就不得不提谷歌了。在这场凌晨的狂欢里,Gemini 3 Pro 显得有点格格不入。
虽然谷歌一直宣传多模态能力,但在开发者最关心的“干活”能力——也就是编程和复杂逻辑推理上,Gemini 3 Pro 目前是掉队的。在 Terminal-Bench 2.0 里,它只有 56.2% 的分,被 GPT-5.3 的 77.3% 甩开了一大截。
而且,虽然 Gemini 号称支持超长上下文,但在社区的实际测试中,一旦 token 数量上去,它的“幻觉”和“遗忘”问题比 Claude 严重得多。
现在全行业的目光都盯着传说中的 Gemini 3.5(代号 Snow Bunny)。泄露消息说它会在 2 月中旬发布,将会加入类似 DeepThink 的深度推理模式。
如果谷歌再不拿出点真东西,在编程和生产力这个最赚钱的赛道上,可能真要被边缘化了。
05
思路打开:当 OpenClaw 拿到「无限手套」
我的mac mini 已经到了。
准备装上 OpenClaw,给无限root权限后,用上这两个最新的模型。
它能干嘛?
想象一下。
你只需要输入一句话:“帮我从零搭建一个能跑通的电商独立站,并开始自动选品推广。”
Claude 会瞬间规划出技术栈和商业闭环;
GPT-5.3 会在终端里疯狂敲击代码,部署服务器,申请 API;
而 OpenClaw 则操控着鼠标和键盘,去注册域名、配置 Stripe 收款账号、甚至去社交媒体上自动发帖引流。
它们不知疲倦,不吃不喝,甚至会互相 Code Review。
L4 级无人驾驶的创业就这样开始了???
这,才是 2026 年最性感的打开方式。
原文链接:
评论