
seo应该都知道搜索结果中的网站地址在2013年前左右就加密了。
加密后长这个样:https://www.baidu.com/link?url=NsHkjUPGl_mZhzM-TUlu6ZfyO3os9ubGKhDv9XiMklKxONjEtFTVLyrKWiW50gJzRFL2hChm_hkarUGQkmwPS_
自从加密后,获取着陆页的方法也就千奇百怪了。无数人沉醉于破解等方法。还有直接跳转到着陆页后再获取url,效率低效到难以想象。
解决获取着陆页需要明白以下几点:
1,加密是由服务端做的,啥算法,任何人都不知道。尝试破解,成功几率几乎为0
2, 如果跟随加密URL跳转到着陆页再获取,方法是可以的。但是效率最终会受到目标网站网速的影响。必然效率无法提高。
3,你需要了解web通信http协议
那就让我们来抓包看看吧!
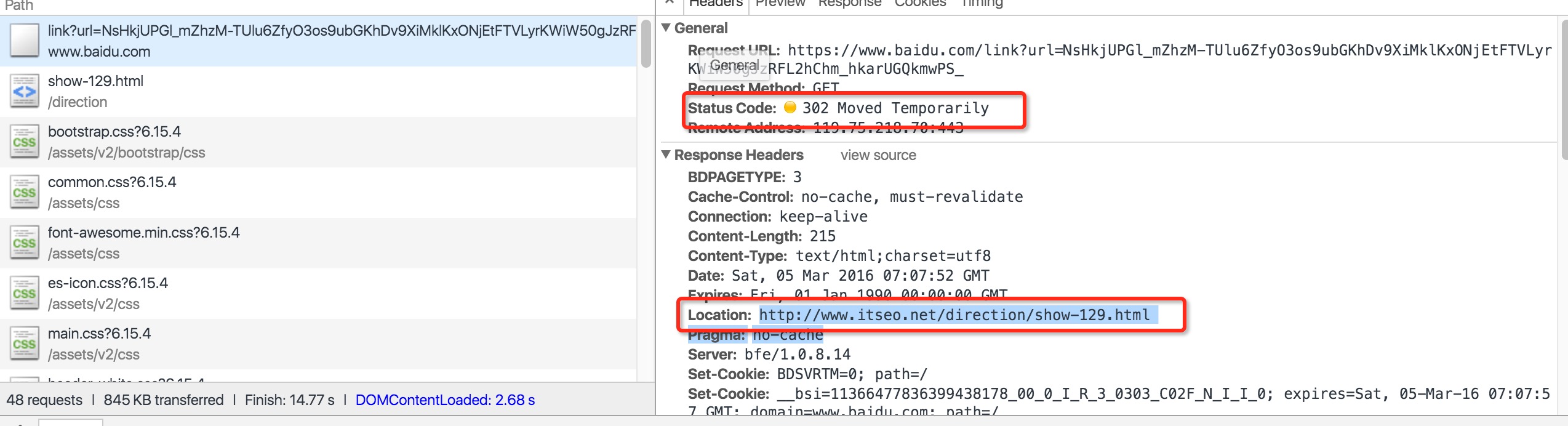
我们可以很清楚的看到这条链接是302跳转链接。而302跳转链接在head中都会带一条location的参数。Location的值就是真实url。
原理就是这么简单。
接下来让我们用一句shell来搞定吧。
curl -s "http://7xq5c6.com1.z0.glb.clouddn.com/url.txt" | awk '{print "curl -sI \""$0"\"| grep Location"}' | sh
java代码:
Connection.Response res = Jsoup.connect("https://www.baidu.com/link?url=NsHkjUPGl_mZhzM-TUlu6ZfyO3os9ubGKhDv9XiMklKxONjEtFTVLyrKWiW50gJzRFL2hChm_hkarUGQkmwPS_").timeout(60000).method(Connection.Method.GET).followRedirects(false).execute();
String str= res.header("Location");
python代码:

php代码
<?php
foreach (file('http://7xq5c6.com1.z0.glb.clouddn.com/url.txt') as $url) {
stream_context_set_default(array('http' => array('method' => 'HEAD')));
$headers = get_headers(trim($url), 1);
echo $headers['Location'];
}
评论